Best practices
-
-
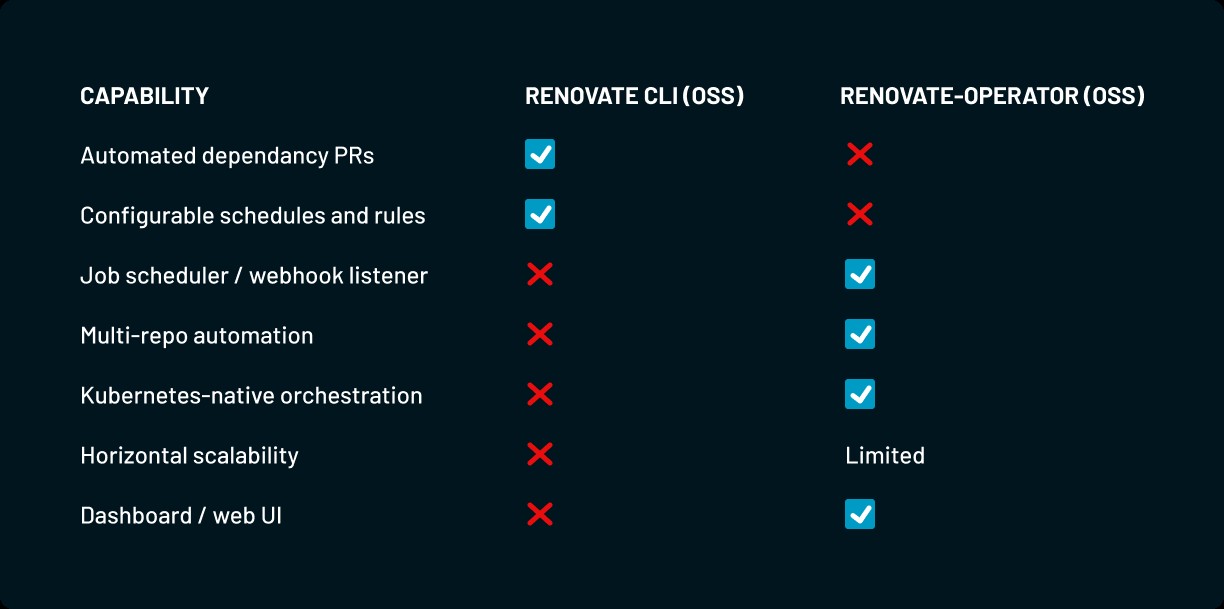
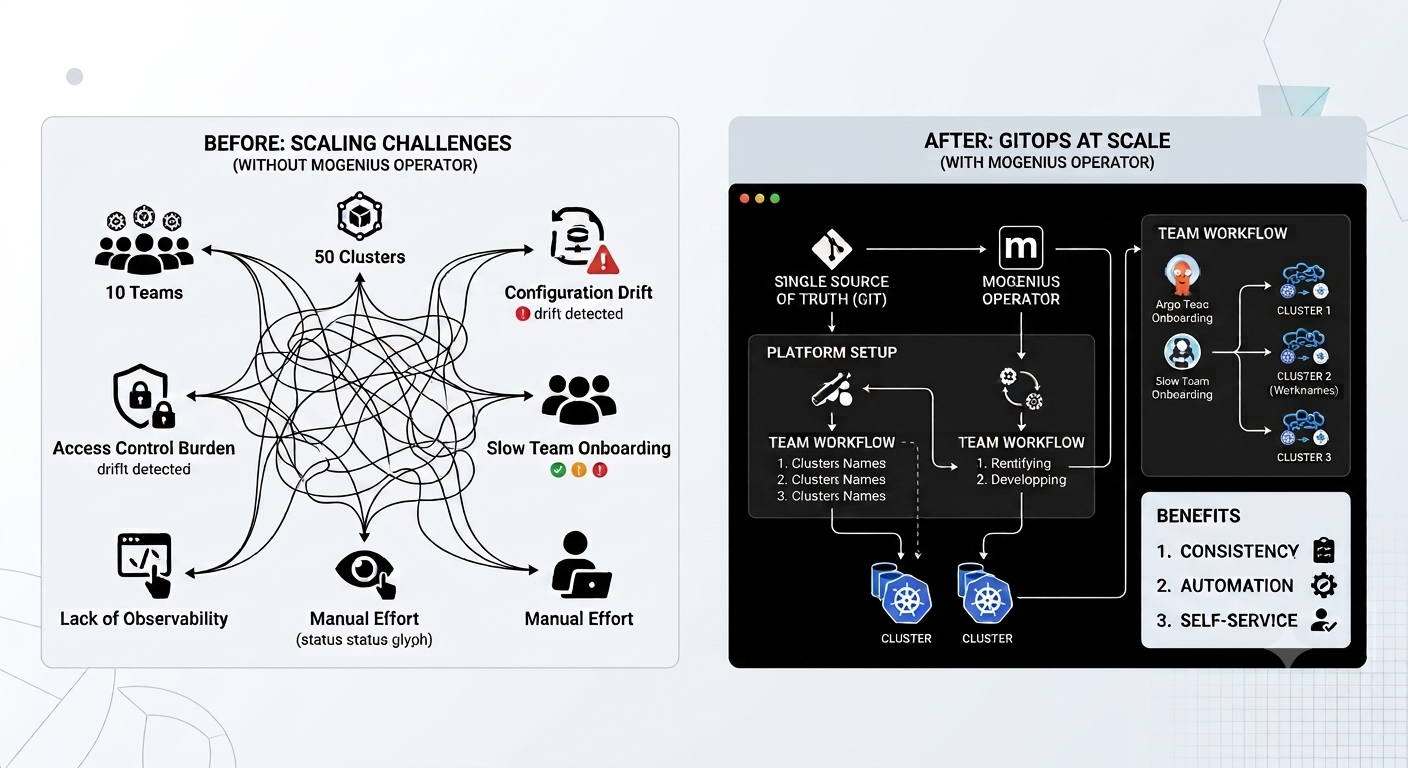
Scaling GitOps with ArgoCD and the mogenius Operator
Discover how ArgoCD and the mogenius Operator scale GitOps across clusters and teams, cutting manual YAML work, drift, and tool sprawl for platform engineers.





Certifications & Memberships






mogenius is a CNCF Silver Member, a Certified Kubernetes product, and ISO 27001 certified via TÜV Saarland.